
The Stack Is Talking. Nobody Is Listening in the Right Order.
Here is what a mature MarTech stack actually looks like:
Your GA4 funnel exploration is showing a 54% drop between the product page and the add-to-cart on mobile. Session recordings are showing users scrolling past the buy button, looking for delivery information that is not on the page. Your event tracking is capturing rage clicks on a form field that validates inconsistently. The heatmap on the category page shows that 38% of desktop visitors never reach the product grid, and they leave from above the fold. The A/B testing tool has 23 ideas in the backlog, submitted by three teams across four weeks.
Every one of those signals is real. Each represents revenue leaving the funnel and shows the real value of a funnel drop-off analysis.
This is the problem that prioritization frameworks exist to solve. Not the testing, not the analysis, but the sequencing: deciding, with defensible logic, which signal to act on, in which order, and why that order is right given this quarter’s objectives, this week’s engineering capacity, and the current state of the funnel.
Without that logic, the test that runs first depends on the gut or the easiest to fix. Without a prioritization framework, the test that runs first is the one the most senior person in the last meeting was most excited about. That is not a strategy. It is organizational gravity.
In ep 16, we covered how to build an experimentation roadmap that connects findings to a quarterly plan that leadership can fund. This episode covers the mechanism that orders that plan: ICE scoring, how to use it so the numbers mean something, when to evolve past it, and how to maintain a calendar that compounds without manufactured velocity.
What ICE Actually Measures (and What It Does Not)
ICE: Impact, Confidence, Ease – a mechanism that converts the raw signal output of a MarTech stack into an ordered, defensible testing agenda.
It does not tell you what is wrong with your site – your CRO audit does. It does not tell you how to build the test – your roadmap does that. What ICE tells you is which problem, surfaced by which signal, deserves the next available test slot, and why.
ICE scores every test idea across three factors, averaged into a single number that ranks the backlog.

- Impact asks: if this test wins, how much does it move the primary metric? This is a function of two things: how much traffic hits the page or step being tested, and how close that step is to the conversion event. A test on a checkout completion step with 3,000 daily sessions has a structurally higher Impact ceiling than a test on a category filter with 200. The score should reflect the math, not the enthusiasm.
- Confidence asks: how strong is the evidence that this change will produce the predicted behavior? Evidence quality exists on a hierarchy. Quantitative funnel data from your own analytics sits at the top. Session recordings and heatmap patterns sit below that. Exit survey responses below that. A competitor observation or industry benchmark belongs near the bottom. The source of the hypothesis, not the strength of the feeling about it, determines the Confidence score.
- Ease asks: how much resource does this test require to build, QA, and launch? This is the dimension most often scored by the wrong person. Marketing estimates Ease optimistically because they want to run the test. Engineering estimates it accurately because they have to build it. Ease must be scoped by the team doing the build before the score is assigned.
Average Impact, Confidence, and Ease. That number ranks the backlog. The highest-ranked tests enter the calendar first.
How ICE Exposes MarTech Maturity
Here is the uncomfortable truth about ICE: it does not hide infrastructure gaps. It amplifies them. A team with clean GA4 event tracking, a behavioral research practice, and engineering in the prioritization conversation produces scores that genuinely sequence the backlog by revenue opportunity. A team without those things produces scores that reflect organizational hierarchy and wishful thinking, just with numbers attached.
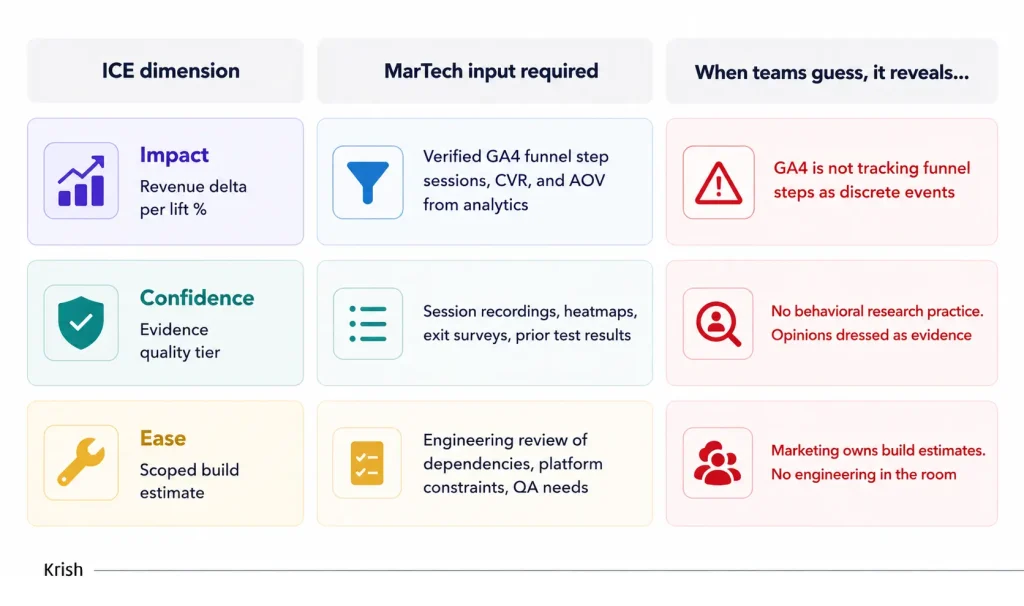
The ICE session is diagnostic. Watch what happens when the team tries to score Impact and nobody can agree on the daily session volume at the specific funnel step because GA4 is not tracking it. That is not an ICE problem. That is a GA4 configuration problem that was invisible until it was time to make a revenue-based decision. ICE makes it visible. Fix the infrastructure first, then run ICE. In that order.
When to go beyond ICE
ICE works because it is fast and creates a shared language. It stops working when more than three or four people are scoring independently, because the same subjective 1–10 scales produce different numbers from different brains. Not because anyone is dishonest, but because “high impact” means different things to a CMO and a UX researcher.
This is the moment to graduate to PXL, developed by Peep Laja and the CXL team. Read the original framework.
PXL replaces ICE’s three subjective scales with a set of binary yes/no questions. Each with an objectively verifiable answer:
- Is the change above the fold on the primary tested device?
- Is it noticeable within five seconds?
- Does it add or remove an element rather than modify one?
- Is it grounded in quantitative data from your own analytics?
- Does it run on a high-traffic page or funnel step?
Two people scoring the same hypothesis under PXL land on nearly identical totals. Because there is no room to debate whether something is above the fold. It either is, or it is not.
PXL also has a hidden benefit in MarTech programs: it creates a feedback loop between the research stack and the testing stack. Because every PXL score requires you to verify the evidence source before assigning a point, teams that cannot score PXL honestly quickly realize their research infrastructure has gaps – which is the point. The scoring framework becomes a forcing function for the behavioral research practice that should have been upstream of it.
When to use which:
- ICE in the first year: the program is building velocity, internal credibility, and a scoring culture. Speed matters more than precision.
- PXL from year two: multiple scorers, a deep backlog, stakeholders who scrutinize test selection. Precision now matters more than speed.
The transition itself is worth communicating to leadership. It means the program has matured past “should we be testing?” to “which well-evidenced test deserves the next slot?” That is a different organizational conversation entirely.
Quick Wins vs Strategic Bets
The gravitational pull of every CRO calendar is toward what is easiest to ship. A copy change takes two days to build and two weeks to read. A checkout flow restructure takes three weeks to build, five weeks to reach statistical significance, and carries real risk of a negative result. On paper, the quick win wins every time.
The trap is invisible until the management asks a sharp question.

Six months into the program, the team presents a 40% win rate and a series of 6–9% lifts in click-through and add-to-cart rates. The CMO asks: what has checkout completion rate done? What has revenue per session moved? If the honest answer is “the engagement metrics improved but the downstream revenue metrics have not materially shifted,” the program has been active without being impactful. It has been optimizing the signals without moving the outcome.
This is the quick-win trap. It looks like success until someone asks the right question.
The way out is not to stop running quick wins. It is to protect 30% of the calendar for structural experiments – tests that interrogate the fundamental architecture of a conversion step, not the surface elements within it. A test restructuring the mobile checkout based on documented funnel drop-off patterns and confirmed by session recordings. A test that changes what information is available at the product page decision moment, informed by the 28-point conversion audit. These carry a lower per-test win probability and a longer build cycle. When they win, the revenue delta is in a different category entirely.
The 70/30 split is not a formula. It is a forcing function. It makes the decision to run a structural experiment explicit rather than letting it perpetually lose to the next easy test. The quick wins build the organizational patience for the longer bets. The strategic bets produce the results that justify the budget. Neither works without the other.
Analysis Paralysis: The Three-Point Readiness Test
There is a failure mode that looks like rigor. The backlog gets scored, questioned, rescored. Every hypothesis draws another round of “we need more data.” The calendar stays empty while the team debates methodology.
The readiness question is not “is this hypothesis perfect?” It is “do we have enough to justify the traffic cost of running this test?” Two different thresholds. One has a clear answer.
Before any test enters the calendar, three conditions must be met:
- The problem is sourced, not assumed.
The hypothesis connects to a specific named data point: a GA4 funnel step with a documented drop rate, a session recording pattern with a described behavior, an exit survey response with a sample count. If the problem statement cannot be traced to a data source, the diagnosis is incomplete. Funnel drop-off data that has not been properly interrogated is not a source – it is a starting point for investigation. - The hypothesis is fully written.
Observed problem. Proposed change with a stated mechanism, not just what changes but why that change addresses the specific behavior observed. Expected outcome scoped to a named metric, a named audience segment, and a magnitude. A hypothesis that cannot be written this way is not ready to score, let alone schedule. - The traffic math has been run.
Not estimated. Calculated. Sample size calculator, 95% confidence, stated MDE, daily sessions to the specific page from GA4. If the result is 11 weeks, that is a planning input. Adjust the MDE, accept the timeline, or find a higher-traffic funnel step. The calculation makes the constraint explicit. What does not close the constraint is running the test anyway on insufficient traffic and calling an inconclusive result a loss.
All three checked: the test is ready.
The Rolling Calendar
The rolling calendar is the operational mechanism that separates an experimentation program from a series of disconnected experiments. It does two things: prevents audience contamination from concurrent tests, and protects the program from the mid-quarter pivot that collapses carefully planned sequencing.
The structure that works:
Maintain a 13-week view, updated at the start of each month. It should show:
- Currently live tests with target close date, primary metric, and audience segment
- Tests in build or QA with planned launch dates
- Tests in ideation with readiness status against the three-point check above
- Paused or retired slots with the reason documented
The 13-week window is deliberate. Long enough to show leadership a full quarter of planned activity. Short enough that the plans remain connected to the current funnel reality.
Preventing contamination:
No two tests should share more than 20% of their target audience. Two tests running simultaneously on the checkout flow to the same traffic segment produce results neither team can cleanly interpret. The calendar makes overlap visible before it becomes a data integrity problem.
Defending against organizational pressure:
The most consistent threat to a rolling calendar is not a lack of ideas. It is the unplanned priority insertion: a new product launch that “needs a test,” a campaign deadline that reshapes the audience, a stakeholder who wants to know why their idea is not running yet.
The defense is practical, not bureaucratic. Show, in the calendar, what inserting an unplanned test costs: which planned test gets bumped, which audience gets further split, what happens to the Minimum Detectable Effect (MDE) for the experiments already running. When the cost is explicit, the conversation changes. Leadership evaluates mid-quarter requests differently when the tradeoff is named rather than absorbed silently.
Finally: What Prioritization Can and Cannot Do
A prioritization framework is an infrastructure for making sequencing decisions defensible. What it is not is a substitute for the evidence base that makes the hypotheses worth running.
The most important upstream investment in any experimentation program is the quality of the research that generates hypotheses. A rigorously scored test built on weak evidence fails. A test built on strong behavioral data from funnel analysis, heatmap and session recording work, and structured audit methodology performs at a structurally higher win rate because the prioritization framework did not produce the evidence.
ICE sequences the queue. Evidence determines what is in it. The programs that compound quarter over quarter have both.
Table of Content
Subscribe with Us!
Never miss any post, stay tuned!
Ankit helps brands navigate their digital maturity journey by bringing together analytics, CRO, ML, and AI in a practical, business-friendly way. Having worked with global teams across industries, he focuses on simplifying complex MarTech concepts and turning them into measurable outcomes. On weekends, you’ll likely find him deep in a reflective read or sharing a coffee with a client while simplifying MarTech in the most human way possible.
Recommended Reading:

What Is Agentic Commerce? A Practical Guide for Ecommerce Leaders – Agentic Commerce Series | EP 1
22 June, 2026 That agent will research, compare, and buy on their behalf without clicking through your homepage, reading your PDPs, or experiencing your brand the way you designed it to be experienced. And when it is done, it will report back as “purchased”.
Subscribe with Us!
Never miss any post, stay tuned!
Trusted by leading brands



